
November 5, 2025
Are Online PDF Editors Really Safe? A Cyber-Security Engineer’s Deep Dive
Introduction
Online PDF editors have quietly become part of everyone’s workflow — whether it’s a recruiter merging résumés, a manager redlining contracts, or a student compressing assignments before a deadline. The convenience is undeniable: drag, drop, edit, download, done. But PDF editor security risks creep in the moment you upload: storage you don’t control, parsing engines you can’t audit, and links that can linger.
When you upload a document to an online PDF editor, you’re essentially handing your file to someone else’s infrastructure — storage, processing, and all. You don’t know where it’s stored, who can access it, or how long it sticks around. And in a world where PDFs can contain hidden scripts, embedded media, and even malicious payloads, the attack surface isn’t trivial.
The question isn’t whether online PDF editors are risky — everything online carries some level of risk. The question is how those risks map to different users and environments. For a casual user editing a travel form, the impact might be negligible. For a company handling contracts, financials, or personally identifiable information, that same upload could become a compliance nightmare or a potential data leak.
In this analysis, we’ll unpack what really happens behind the scenes when you use these tools, explore the attack vectors that matter, and look at what mitigations can make the difference between “safe enough” and “security disaster.”
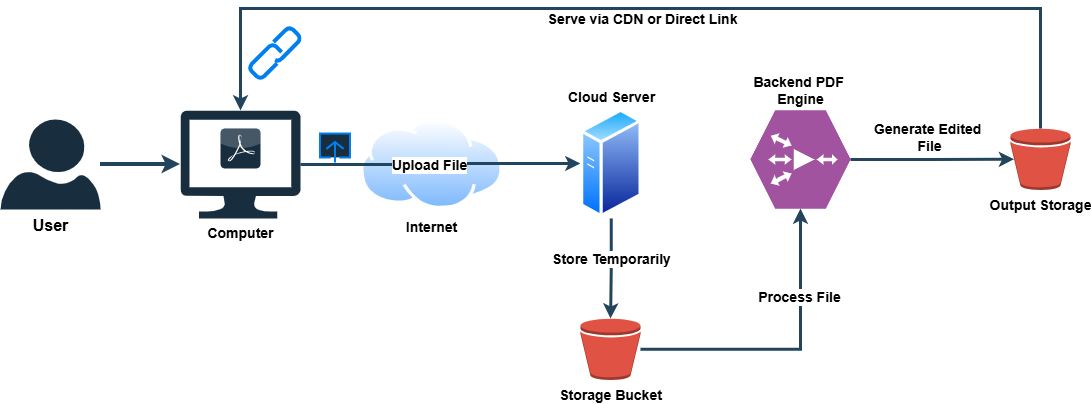
How Online PDF Editors Work Under the Hood
At first glance, online PDF editors feel like magic. You upload a file, tweak it in the browser, and download a finished version seconds later. But under that smooth UX is a complex web of infrastructure that touches multiple layers of the internet — and every one of those layers introduces potential security considerations.
1. The Upload Phase
When you hit “upload,” your file is sent to a remote server over HTTPS. Ideally, it’s encrypted in transit via TLS, but that’s only part of the story. Once the file lands on the server, it’s typically stored in a temporary bucket or cache so the backend service can process it. Some platforms delete these files after a session ends; others keep them “for performance and recovery.” That phrase should already set off red flags — if there’s retention, there’s exposure risk.
2. The Processing Layer
Most online editors don’t actually “edit” in your browser — they process the file server-side. The backend usually uses libraries like PDFBox, iText, or proprietary parsing engines to render and manipulate document objects. During this stage, metadata and document structure are fully exposed to the service provider. In the worst-case scenario, this is where a malicious actor with backend access could extract sensitive text, embedded images, or form data.
There are newer client-side models, though — using WebAssembly (WASM) or sandboxed JavaScript runtimes — that handle PDF parsing entirely in the browser. These are far safer because the file never leaves your machine, though they’re still uncommon due to heavier CPU and memory requirements.
3. The Download / Delivery Phase
Once you’re done editing, the final PDF is rendered and stored temporarily for download. This often triggers caching, CDN delivery, or short-lived object URLs. If access control on these URLs isn’t properly implemented — think predictable URLs or unexpired tokens — your “private” document could easily be accessible to anyone who stumbles across the link or sniffs traffic on a compromised endpoint.
4. The “Forgotten” Data Trail
Logs, temp files, backups, analytics — every component that touches the PDF might hold traces of it. Even if a provider deletes the original file, system-level snapshots or third-party integrations (cloud storage, CDN analytics, load balancers) may still retain fragments. This is where compliance frameworks like GDPR, HIPAA, and SOC 2 become relevant — not because they make platforms perfectly safe, but because they define how bad things can legally get when data lingers longer than intended.
In short, the magic of online PDF editing relies on heavy server-side handling, and that’s exactly where your control ends. Knowing this workflow is crucial because every risk — interception, unauthorized access, data leakage — stems from one of these stages.
Security Threat Landscape
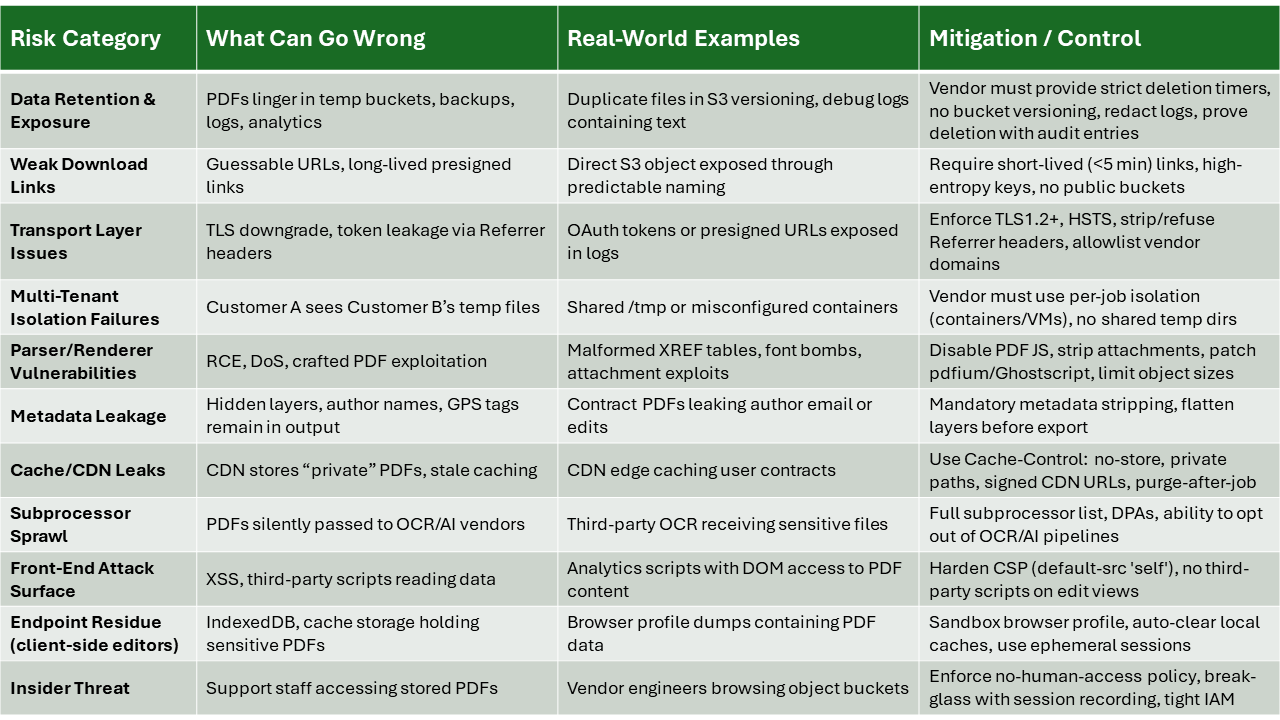
Let’s map the real attack surface like we’d threat-model a SaaS doc pipeline. Impact depends on your data class and the editor’s architecture (server-side vs client-side/WASM), but the vectors are pretty consistent.
1. Data exposure & persistence
-
Retention creep: “Temporary” buckets, build artifacts, and object-storage versioning keep ghosts of your PDFs. Snapshots/backups multiply them.
-
Over-broad logging: Debug logs, APM traces, and error dumps can capture filenames, extracted text, or presigned URLs.
-
Jurisdiction drift: Multi-region storage moves data across borders, complicating GDPR/DSARs and contractual controls.
2. Transport & session risks
-
TLS misconfig / downgrade windows: Rare with modern stacks, but still a risk on edge cases (legacy clients, mis-issued certs).
-
Bearer token leakage: Presigned download links copied into tickets/Slack or leaked via
Refererheaders to third-party pixels. -
Weak link entropy: Predictable object keys or long-lived presigned URLs → drive-by discovery.
3. Access control & tenancy
-
Broken object ACLs: Incorrect bucket policies or CDN rules expose “private” outputs.
-
Multi-tenant bleed: Parser/renderer mis-isolation lets one tenant peek at another tenant’s temp files (container escape, shared
/tmp). -
Insider threat: Console access, broad IAM roles, or contractors scraping “for QA.”
4. Supply chain & third parties
-
CDN/edge plugins: Transform functions at the edge can log or cache content unexpectedly.
-
Sub-processors: OCR, e-signature, or “AI cleanup” vendors receive copies; each adds its own risk/compliance surface.
-
Library vulns: PDF stacks (pdfium, iText/PDFBox, Ghostscript, libjpeg/libpng, image codecs, font engines) are historically juicy CVE territory.
5. Malicious document payloads
-
Parser RCE/DoS: Crafted PDFs (overlapping objects, huge nested streams, zip-bomb-style embeds) can crash or pop the renderer.
-
Embedded JavaScript & actions: PDF JS,
/Launch, external links, and file attachments can trigger naughty flows if not stripped. -
Font/codec shenanigans: Malformed fonts/images exploit native decoders during rasterization or thumbnailing.
-
Inbound → outbound taint: Service re-emits the weaponized file back to your users (“clean” output still hostile).
6. Output & delivery layer
-
Cache leaks: Public cache keys, stale objects, or wrong
Cache-Controlexposing private outputs. -
URL spraying: Guessable IDs; search engines indexing if headers are wrong.
-
Watermark/meta leaks: Output keeps source metadata, hidden layers, or XMP fields you thought were gone.
7. Client-side (WASM/in-browser) editors
-
Local residue: Files in IndexedDB/Cache Storage/tmp dirs; crash dumps or memory captures on managed endpoints.
-
XSS/CORS mishaps: If the app loads third-party scripts, edited content or presigned URLs can leak cross-origin.
-
Supply-chain on the front end: NPM deps or injected analytics with excessive privileges.
8. Compliance & process
-
Policy mismatch: “We delete in 2 hours” ≠ your contractual duty for PII/PHI or legal hold.
-
Audit gaps: No access logs, no per-object trails, no evidence for DPA/SOC2 controls.
-
Key management theater: “Encrypted at rest” with provider-managed keys and broad operator access.

Environment Controls
1. Architecture choices
-
Prefer client-side editors (WASM/in-browser) for anything ≥ “internal” sensitivity. No upload, no problem.
-
If server-side is unavoidable, route via an egress allowlist proxy so only your chosen vendor sees traffic.
-
Self-host where feasible (containerized PDF toolchain behind your WAF) for regulated data.
2. Network & transport
-
Enforce TLS 1.2+, HSTS, OCSP stapling; fail closed on cert errors at the proxy.
-
Strip
Refererand setReferrer-Policy: no-referreron your side to avoid leaking presigned URLs. -
For SaaS: require short-lived presigned URLs (≤ 5 min), high-entropy object keys, and no public buckets.
3. Storage, retention, and redaction
-
Contract explicit retention: e.g., delete originals & derivatives within 60 minutes of job completion; logs redact content; backups exclude object buckets.
-
Demand per-object deletion proofs (audit entries you can export).
-
Ensure server-side encryption with customer-managed keys (CMEK) or at minimum tenant-scoped KMS keys; log every decrypt.
4. Access control & tenancy
-
Require SAML/SCIM with RBAC; no shared vendor accounts.
-
Vendor IAM: least privilege roles for workers; deny list-objects on buckets users don’t own; isolate tmp dirs per job/container.
-
No human access by default; break-glass with approvals and session recording if support must touch data.
5. Parser hardening
-
Disable PDF JavaScript,
/Launch, embedded files by default on ingest. -
Flatten forms & layers; convert to raster for preview when possible.
-
Cap object/stream sizes; reject suspicious structures (overlapping xref, excessive nesting, zip-bomb patterns).
-
Keep pdfium/Ghostscript/PDFBox fully patched; subscribe to their CVE feeds.
6. Output & delivery
-
Force
Cache-Control: private, max-age=0, no-storeon downloads. -
Ensure unindexed links (
X-Robots-Tag: noindex, nofollow). -
Watermark internal downloads if you care about leak attribution; strip XMP/metadata on output.
7. Front-end (for client-side editors)
-
Content Security Policy (tight):
default-src 'self'; script-src 'self'; connect-src 'self' vendor-api.example; object-src 'none'; frame-ancestors 'none' -
No third-party analytics with doc access. Audit NPM deps; pin versions; verify WASM hashes (
integrityattributes).
8. Endpoint hygiene
-
Run editors inside sandboxed browsers/profiles; clear IndexedDB/Cache Storage post-session.
-
EDR allow-but-monitor; block document launch to shell from PDFs; disable OS-level auto-previewers for untrusted sources.
Quick Vendor RFP/RFI checklist
Data handling
-
Exact retention timers for originals, derivatives, logs, backups.
-
Region pinning & list of sub-processors (with DPAs/SCCs).
-
CMEK support or tenant-scoped KMS; key-access audit available.
Security controls
-
SOC 2 Type II / ISO 27001 reports (recent).
-
Vulnerability disclosure policy + cadence of library patching.
-
Per-object access logs exportable (user, IP, time, action).
-
No human access by default; JIT/break-glass with recording.
App specifics
-
PDF JS disabled by default; attachments stripped unless allowed.
-
Multi-tenant isolation model (namespaces, containers, fs isolation).
-
Short-lived presigned URLs (≤5 min) and randomized object names.
-
Cache-ControlandX-Robots-Tagon outputs; CDN config proof.
Support & incidents
-
24/7 incident response, RTO/RPO, and customer-impact comms SLAs.
-
Forensics: can they provide per-job deletion evidence and object lineage?
-
Breach notification timelines aligned with your jurisdictional regs.
Decision guide
-
Public/low-sensitivity (flyers, homework): client-side preferred; reputable SaaS ok with short-lived links.
-
Internal/PII/contracts: client-side or self-host; if SaaS, require DPA, CMEK, strict retention, audit logs.
-
Regulated (PHI/finance/legal hold): avoid third-party server-side editors; self-host hardened toolchain behind your WAF.
One-minute teardown for any online editor
-
Open DevTools → Network: watch for third-party domains, presigned URLs, caching headers.
-
Try shareable links after 10 minutes: still valid? indexed? cacheable?
-
Drop a PDF with JS/attachments: are they blocked/stripped?
-
Ask support for retention timers and sub-processor list: time their response and check for substance.
-
Request a sample audit log for a single job: if they can’t produce it, that’s your answer.
Real-World Attacks Via PDFs & PDF Toolchains
-
Adobe Acrobat/Reader zero-day (CVE-2023-26369): Out-of-bounds write in font handling let attackers get code execution via a booby-trapped PDF; Adobe confirmed in-the-wild exploitation.
-
Ghostscript sandbox bypass (CVE-2024-29510): The workhorse behind many server-side PDF pipelines had an RCE bug actively exploited, making “upload → convert” services a prime target.
-
Chrome/PDFium bugs abused by crafted PDFs (e.g., CVE-2024-5847, CVE-2024-7973): Use-after-free/heap issues in PDFium allowed malicious PDFs to corrupt memory and potentially execute code until patched.
-
Trojanized “PDF editor” malvertising (TamperedChef / AppSuite PDF Editor): A fake editor pushed via ads installed an info-stealer that lay dormant ~2 months before exfiltrating creds and cookies.
-
Supply-chain splash damage in doc pipelines: Ghostscript/ImageMagick integrations used by converters and previewers expanded blast radius—one library vuln risks the whole SaaS workflow.
What Can you Do?
Organizations don’t have to sit in the splash zone of these attacks if they invest in the right defensive muscle. Logstail Academy gives teams a place to level up fast — practical, threat-driven training that teaches employees how to spot malicious documents, avoid sketchy “free editors,” and follow workflows that don’t leak sensitive data all over the internet. Pair that with Logstail SIEM Platform and you get continuous visibility across your stack: real-time log correlation, anomaly detection, and alerting that actually catches PDF-based exploitation attempts before they turn into a breach. One side trains your people to stop opening the wrong doors; the other side watches the doors nonstop. Together, that combo turns a risky document workflow into a monitored, hardened, grown-up security posture.
Conclusion
Online PDF editors aren’t inherently evil — they’re just built on layers of infrastructure that most people never think about. And inside those layers live storage buckets, parsing engines, CDNs, third-party processors, and logs that definitely don’t care about your compliance obligations. When the workflow is “upload → process → download,” you’re outsourcing trust to a system you can’t see and can’t control. Sometimes that’s fine. Sometimes that’s how breaches start.
Once you break the workflow down, the pattern is obvious: the risk isn’t the PDF itself, it’s the ecosystem around it. Server-side editors explode your threat surface, client-side editors shrink it, and hybrid platforms dance somewhere in the middle. The smart move is to build guardrails around the workflow instead of pretending it’s safe by default. Harden the environment, demand transparency from vendors, and treat any “free” or opaque tool as a potential leak vector until proven otherwise.
At the end of the day, security comes down to two things: people and visibility. Train your teams so they aren’t tricked by malicious files, and monitor your systems so you’re not relying on hope as a defense strategy. With the right awareness and the right detection pipeline, even a risky workflow becomes manageable. Without them, you’re just crossing your fingers every time someone uploads a contract.
That’s the difference between surviving the modern threat landscape and becoming part of someone’s breach report.
Contact Our Experts or Sign Up for Free