
February 6, 2020
What is Filebeat and why is it important?

The Elastic Stack today is comprised of four components, Elasticsearch, Logstash, Kibana, and Beats. The last one is a family of log shippers for different use cases and Filebeat is the most popular. If you want to get started with Filebeat, read this short article to get informed about the basics of installing, configuring and running in order to obtain the full potential of your data! 
What is Filebeat and where is it used?
Generally, the beats family are open-source lightweight data shippers that you install as agents on your servers to send operational data to Elasticsearch. Beats can send data directly to Elasticsearch or via Logstash, where you can further process and enhance the data (image). The beats Family consists of Filebeat, Metricbeat, Packetbeat, Winlogbeat, Auditbeat, Journalbeat, Heartbeat and Functionbeat. Each beat is dedicated to shipping different types of information — Winlogbeat, for example, ships Windows event logs, Metricbeat ships host metrics, and so forth. Filebeat is designed to ship log files. Filebeat helps keep things simple by offering a lightweight way (low memory footprint) to forward and centralize logs and files, making the use of SSH unnecessary when you have a number of servers, virtual machines, and containers that generate logs. Other benefits of Filebeat are the ability to handle large bulks of data, the support of encryption, and deal efficiently with backpressure. Essentially, Filebeat is a logging agent installed on the machine generating the log files, tailing them, and forwarding the data to either Logstash for more advanced processing or directly into Elasticsearch for indexing. At this point, we want to emphasize that Filebeat is not a replacement for Logstash, but it should be used together to take advantage of a unique and useful feature. Filebeat uses a backpressure-sensitive protocol when sending data to Logstash or Elasticsearch to account for higher volumes of data. If Logstash is busy processing data, it lets Filebeat know to slow down its read. Once the congestion is resolved, Filebeat will build back up to its original pace and keep on shipping.
Yes, but what is a Beats module?
Very interesting is the fact that Filebeat comes with internal modules for Apache, Nginx, MySQL and more, that simplify the collection, parsing, and visualization of common log formats down to a single command. These support modules are built-in configurations and Kibana objects for specific platforms and systems and can be utilized easily because they come with pre-configured settings and they can also be later adjusted according to the organization’s needs. Additionally, a few Filebeat modules ship with pre-configured machine learning jobs. A list of the different configurations per module can be found in the /etc/filebeat/module.d (on Linux or Mac) folder. Modules are disabled by default and need to be enabled. There are various ways of enabling modules, one way being from your Filebeat configuration file:
filebeat.modules: - module: apache
The downside of Filebeat modules is that it is a bit difficult to use since it requires using Elasticsearch Ingest Node and some specific modules have additional dependencies. Also, keep in mind that the users of Logstail.com do not need to enable and configure the Filebeat module (very important!). Today, Filebeat supports 36 different modules and Metricbeat 48.
How to install Filebeat
Filebeat can be downloaded and installed using various methods and on a variety of platforms. It only requires that you have a running ELK Stack to be able to ship the data collected by Filebeat.
Install Filebeat using Apt
The most convenient way to install the Filebeat is with the use of Apt or Yum from Elastic’s repositories. First, you need to add Elastic’s signing key so that the downloaded package can be verified (skip this step if you’ve already installed packages from Elastic):
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
The next step is to add the repository definition to your system:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Lastly, update your repositories and install Filebeat:
sudo apt-get update && sudo apt-get install filebeat
How to Configure Filebeat
Filebeat is relatively easy to configure, and also they all follow the same configuration setup. Filebeat is configured using a YAML configuration file. On Linux, this file is located at:
/etc/filebeat/filebeat.yml
YAML is syntax sensitive and you cannot use tabs for spacing. Filebeat contains many configuration options, but in most cases, you will only need the very basics. For your convenience, you can refer to the example filebeat.reference.yml configuration file which is located in the same location as the filebeat.yml file, that contains all the different available options. The main configuration units are inputs, processors and output. Let’s take a closer look at them.
1) Filebeat inputs
Filebeat inputs are responsible for locating specific files and applying basic processing to them. From this point, you can configure the path (or paths) to the file you want to track. Also, you can use additional configuration options such as the input type and the encoding to use for reading the file, excluding and including specific lines, adding custom fields, and more.
filebeat.inputs: - type: log #Change value to true to activate the input configuration enabled: false paths: - “/var/log/apache2/*” - “/var/log/nginx/*” - “/var/log/mysql/*”
Paths can be edited to include other inputs (defined by -) for crawling and fetching. The input here for Apache creates a directory called apache2. The next Nginx, then Mysql, and so on.
2) Filebeat processors
Filebeat can process and enhance the data before forwarding it to Logstash or Elasticsearch. This feature is not as good as Logstash, but it is useful. You can decode JSON strings, drop specific fields, add various metadata (e.g. Docker, Kubernetes), and more. Processors are defined in the Filebeat configuration file per input. You can define rules to apply your processing using conditional statements. Below is an example using the drop_fields processor for dropping some fields from Apache access logs:
filebeat.inputs: - type: log paths: - "/var/log/apache2/access.log" fields: apache: true processors: - drop_fields: fields: ["verb","id"]
3) Filebeat output
Here you can define where the data is going to be shipped. Most often you will use the Logstash or Elasticsearch output types, but you should know that there are other options such as Redis or Kafka. If you define a Logstash instance you can have advanced processing and data enhancement. Otherwise and if your data is well-structured you can ship directly to the Elasticsearch cluster. Also, you can define multiple outputs and use a load balancing option to balance the forwarding of data. For forwarding logs to Elasticsearch:
output.elasticsearch: hosts: ["localhost:9200"]
For forwarding logs to Logstash:
output.logstash: hosts: ["localhost:5044"]
For forwarding logs to two Logstash instances:
output.logstash: hosts: ["localhost:5044", "localhost:5045"] loadbalance: true
Logstail.com Log Shippers Wizard
To make things even easier for you, Logstail.com provides a predefined Filebeat configuration for every technology integrated with the platform. It can be accessed via the Log Shippers tab in your account.  You can choose the log shipper you are interested in and the instructions will help you to make the correct settings.
You can choose the log shipper you are interested in and the instructions will help you to make the correct settings. 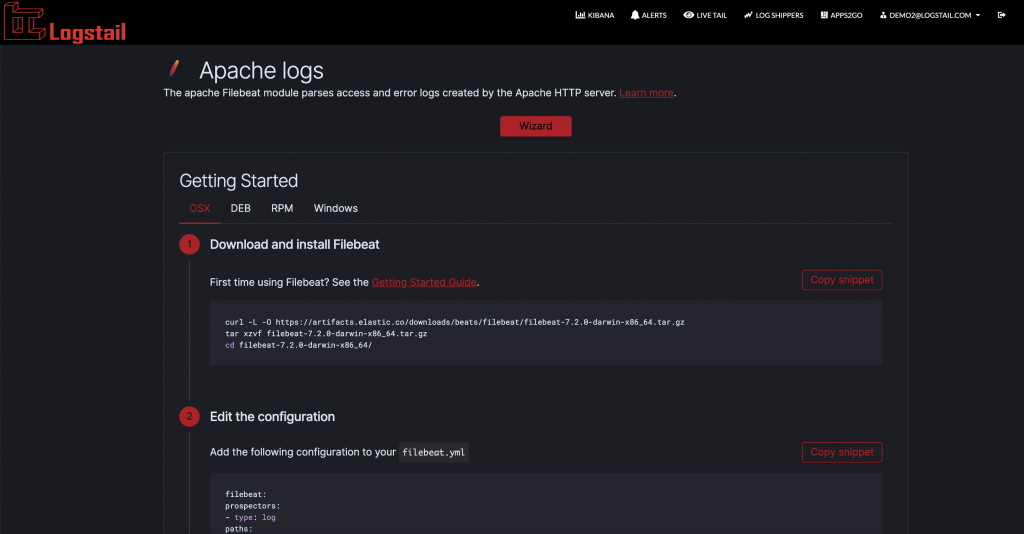
When all steps are complete, you’re ready to explore your data!